Go浅析-WaitGroup
一、结构
WaitGroup 的结构很简单,维护了三个不同的计数,分别是 counter、waiter 和 semaphore:
- counter 记录了要等待结束的 goroutine 个数;
- waiter 记录了等待在该 WaitGroup 上的 goroutine 的个数;
- semaphore 被用作信号量。
但是在 WaitGroup 的结构里并没有直接以这三种变量命名的成员,noCopy 用来告诉代码提示器本结构体变量不能进行值复制,这个暂且略过。在结构体内使用了一个 uint64 和一个 uint32 两个数字来表示了这三个变量,将 counter 和 waiter 两个部分当作了一个 uint64 变量进行操作,semaphore 当作一个 uint32 变量进行操作。
|
|
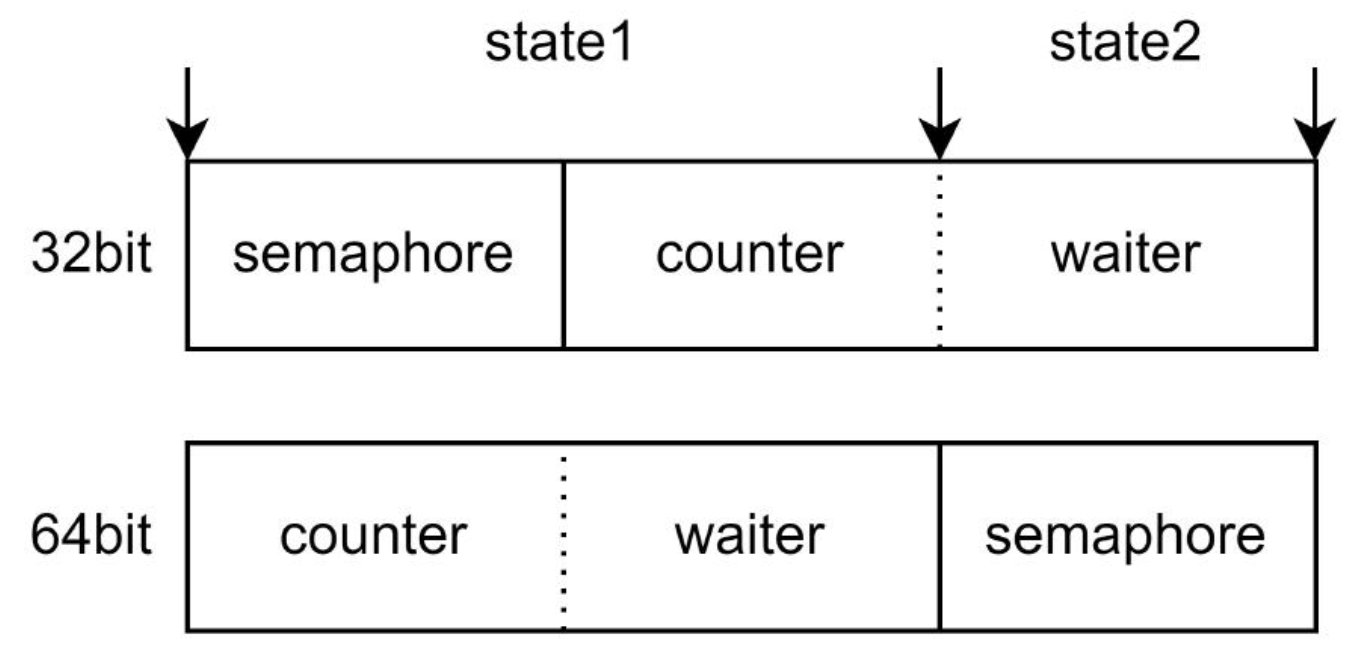
从图中看出,当 state1 是 32 位对齐和 64 位对齐的情况下,state1 中每个元素的顺序和含义也不一样:
- 当
state1是 32 位对齐:state1数组的第一位是 sema,第二位是 waiter,第三位是 counter。 - 当
state1是 64 位对齐:state1数组的第一位是 waiter,第二位是 counter,第三位是 sema。
为什么会有这种奇怪的设定呢?
这里有两个前提:
- 在 WaitGroup 的逻辑中,counter 和 waiter 被合在了一起,当成一个 64 位的整数对外使用。当需要变化 counter 和 waiter 的值的时候,也是通过 atomic 来原子操作这个 64 位整数。
- 在 32 位系统下,如果使用 atomic 对 64 位变量进行原子操作,调用者需要自行保证变量的 64 位对齐,否则将会出现异常。
接下来我们看看 WaitGroup 是如何获取这两部分的地址的,通过 state():
|
|
- 当
state1变量是 64 位对齐时,也就意味着数组前两位作为 64 位整数时,自然也可以保证 64 位对齐了。 - 当
state1变量是 32 位对齐时,我们把数组第 1 位作为对齐的 padding,因为state1本身是 uint32 的数组,所以数组第一位也有 32 位。这样就保证了把数组后两位看做统一的 64 位整数时是64位对齐的。
第一个返回值是 counter 和 waiter 的集合体的指针,第二个返回值是 semaphore 的指针。
注: 有些文章会讲到,WaitGroup 两种不同的内存布局方式是 32 位系统和 64 位系统的区别,这其实不太严谨。准确的说法是 32 位对齐和 64 位对齐的区别。因为在 32 位系统下,state1 变量也有可能恰好符合 64 位对齐。
那为什么要把 counter 和 waiter 合在一起呢?
这其实是 WaitGroup 的一个性能优化手段。因为 counter 和 waiter 在改变时需要保证并发安全。
首先,对于这种场景,我们最简单的做法是,搞一个 Mutex 或者 RWMutex 锁, 在需要读写 counter 和 waiter 的时候,加锁就完事。但是我们知道加锁必然会造成额外的性能开销。
WaitGroup 直接把 counter 和 waiter 看成了一个统一的 64 位变量。其中 counter 是这个变量的高 32 位,waiter 是这个变量的低 32 位。在需要改变 counter 时, 通过将累加值左移 32 位的方式:atomic.AddUint64(statep, uint64(delta)<<32),即可实现 count += delta 同样的效果。
二、Add & Done
之所以将 Add 方法和 Done 方法合在一个分节里,是因为 Done 只是对 Add 的简单调用而已。本节主要来分析一下 Add 方法即可。
Add 方法的作用是修改当前等待结束的 goroutine 的数量,它接受一个参数 delta,这个参数可正可负,也就是说 Add 其实不仅可以增加也可以减少计数,只是一般不会直接使用 Add 来减少计数。
|
|
从上面的源码中可知 Add 不仅修改了计数器 counter,同时也做了计数检查。 如果上面的 if 分支都没有匹配的话,说明 counter 已经等于 0 且 waiter 不等于 0,此时会将 counter 与 waiter 的集合体 statep 重置为 0 方便后续复用该 WaitGroup,然后根据 waiter 保存的计数,依次调用 runtime_Semrelease 触发信号 semap,唤醒所有等待中的 goroutine。
Done就是调用了Add:
|
|
三、Wait
Wait 的作用是将调用该方法的 goroutine 阻塞,等 WaitGroup 中的 counter 计数归零后,会将其唤醒继续执行 Wait 之后的代码。
|
|
在 for 循环中使用 CAS 原子操作,比较并修改 statep 的值,将 waiter 的计数进行累加。然后执行 runtime_Semacquire 将自己阻塞在信号 semap 上,等待唤醒。
四、疑问
4.1 为什么要将 counter 和 waiter 合并?
为什么要煞费苦心将 counter 和 waiter 这两个计数合并成一个 uint64 类型的值?似乎可以用两个 uint32 的值来分开表示,然后在操作各自的时候都使用 uint32 的原子操作即可,这样也不用考虑内存对齐的问题。
主要是需要保证counter与waiter修改时的并发安全。因为 counter 和 waiter 这两个计数在使用时需要匹配才行,如果将这两个计数分开表示,那么就要用两次原子操作读取,在这两次原子操作之间就可能产生一些变化使 counter 和 waiter 不再匹配,从而导致一些难以预料的问题。