[toc]
一、Atomic 方法
如果去看文档会发现 atomic 的函数签名有很多,但是大部分都是重复的为了不同的数据类型创建了不同的签名,这就是没有泛型的坏处了,基础库会比较麻烦
1、第一类 AddXXX,当需要添加的值为负数的时候,做减法,正数做加法
1
2
3
4
5
|
func AddInt32(addr *int32, delta int32) (new int32)
func AddInt64(addr *int64, delta int64) (new int64)
func AddUint32(addr *uint32, delta uint32) (new uint32)
func AddUint64(addr *uint64, delta uint64) (new uint64)
func AddUintptr(addr *uintptr, delta uintptr) (new uintptr)
|
2、第二类 CompareAndSwapXXX,==CAS 操作==,会先比较传入的地址的值是否是 old,如果是的话就尝试赋新值,如果不是的话就直接返回 false,返回 true 时表示赋值成功。
1
2
3
4
5
6
|
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)
func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool)
func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool)
func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool)
|
3、第三类 LoadXXX,从某个地址中取值
1
2
3
4
5
6
|
func LoadInt32(addr *int32) (val int32)
func LoadInt64(addr *int64) (val int64)
func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
func LoadUint32(addr *uint32) (val uint32)
func LoadUint64(addr *uint64) (val uint64)
func LoadUintptr(addr *uintptr) (val uintptr)
|
4、第四类 StoreXXX ,给某个地址赋值
1
2
3
4
5
6
|
func StoreInt32(addr *int32, val int32)
func StoreInt64(addr *int64, val int64)
func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
func StoreUint32(addr *uint32, val uint32)
func StoreUint64(addr *uint64, val uint64)
func StoreUintptr(addr *uintptr, val uintptr)
|
5、第五类 SwapXXX ,交换两个值,并且返回老的值
1
2
3
4
5
6
|
func SwapInt32(addr *int32, new int32) (old int32)
func SwapInt64(addr *int64, new int64) (old int64)
func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer)
func SwapUint32(addr *uint32, new uint32) (old uint32)
func SwapUint64(addr *uint64, new uint64) (old uint64)
func SwapUintptr(addr *uintptr, new uintptr) (old uintptr)
|
6、最后一类 Value 用于任意类型的值的 Store、Load,这是 1.4 版本之后引入的,签名的方法都只能作用于特定的类型,引入这个方法之后就可以用于任意类型了。
1
2
3
|
type Value
func (v *Value) Load() (x interface{})
func (v *Value) Store(x interface{})
|
参考文章:
二、CAS
概述
比较并交换:简称 CAS,这类操作的前缀为 CompareAndSwap,不仅支持对数值类型进行比较交换,还支持对指针进行比较交换:
1
2
|
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
|
该操作在进行交换前:首先确保被操作数的值未被更改,即仍然保存着参数 old 所记录的值,满足此前提条件下才进行交换操作。其实这就是 CAS 汇编代码中 CMPXCHGL 的作用。
CAS的做法类似操作数据库时常见的乐观锁机制。需要注意的是,当有大量的 goroutine 对变量进行读写操作时,可能导致CAS操作无法成功,这时可以利用for循环多次尝试。
实现原理
CAS 的实现思想可用如下伪代码说明:
1
2
3
4
5
6
7
8
|
bool Cas(int *val, int old, int new)
Atomically:
if(*val == old){
*val = new;
return 1;
} else {
return 0;
}
|
以CompareAndSwapInt32为例,它在sync/atomic/doc.go中定义的函数原型如下:
1
|
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
|
对应的汇编代码位于sync/atomic/asm.s中
1
2
|
TEXT ·CompareAndSwapInt32(SB),NOSPLIT,$0
JMP runtime∕internal∕atomic·Cas(SB)
|
通过指令JMP,跳转到它的实际实现runtime∕internal∕atomic·Cas(SB)。底层由汇编代码组成,不同平台可能有所不同,此处用arm64为例:
1
2
3
4
5
6
7
8
|
TEXT runtime∕internal∕atomic·Cas(SB),NOSPLIT,$0-17
MOVQ ptr+0(FP), BX # 第一个参数addr命名为ptr,放入BX(MOVQ,完成8个字节的复制)
MOVL old+8(FP), AX # 第二个参数old,放入AX(MOVL,完成4个字节的复制)
MOVL new+12(FP), CX # 第三个参数new,放入CX(MOVL,完成4个字节的复制)
LOCK
CMPXCHGL CX, 0(BX) # 通过寄存器中的值,比较并交换
SETEQ ret+16(FP)
RET
|
这段汇编代码的含义就是:
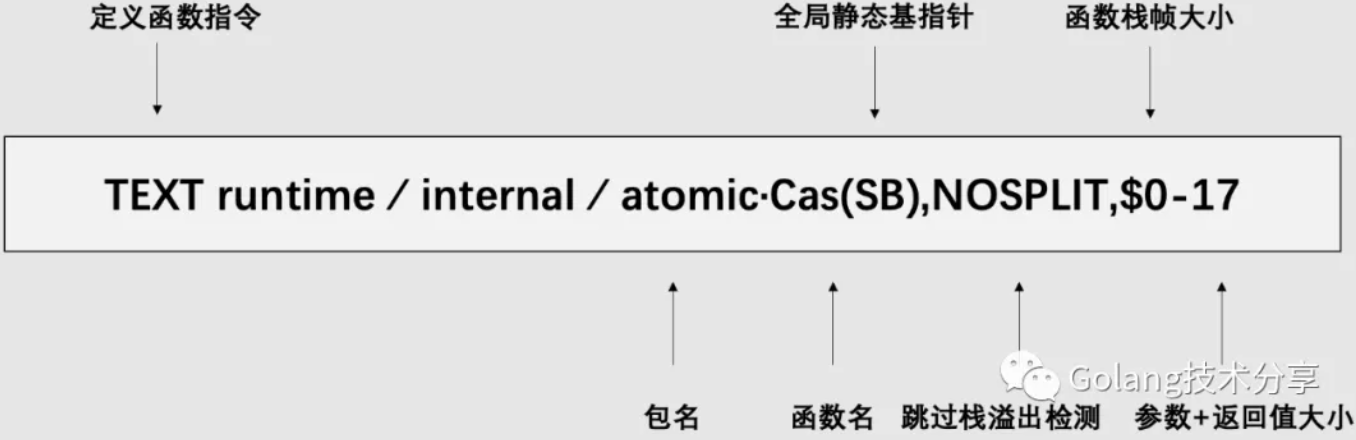
其实没必要完全搞懂上述汇编是啥意思,它的函数原型为func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool),其入参addr为8个字节(64位系统),old和new分别为4个字节,返回参数swapped为1个字节,所以17=8+4+4+1。
接下来解释这几条汇编指令的作用:
ptr+0(FP)代表的意思就是ptr从FP偏移0byte处取内容。AX,BX,CX在这里,知道它们是存放数据的寄存器即可。MOV X Y所做的操作是将X上的内容复制到Y上去,MOV后缀L表示“长字”(32位,4个字节),Q表示“四字”(64位,8个字节)。
1
2
3
|
MOVQ ptr+0(FP), BX # 第一个参数addr命名为ptr,放入BX(MOVQ,完成8个字节的复制)
MOVL old+8(FP), AX # 第二个参数old,放入AX(MOVL,完成4个字节的复制)
MOVL new+12(FP), CX # 第三个参数new,放入CX(MOVL,完成4个字节的复制)
|
- 重点是
LOCK指令:在多处理器环境中,指令前缀LOCK能够确保,在执行LOCK随后的指令时,处理器拥有对任何共享内存的独占使用。在汇编代码里给指令加上 LOCK 前缀,这是CPU 在硬件层面支持的原子操作。但这样的锁粒度太粗,其他无关的内存操作也会被阻塞,大幅降低系统性能,核数越多愈发显著。为了提高性能,Intel 从 Pentium 486 开始引入了粒度较细的缓存锁:MESI协议。此时,尽管有LOCK前缀,但如果对应数据已经在 cache line里,也就不用锁定总线,仅锁住缓存行即可。
1
2
|
LOCK
CMPXCHGL CX, 0(BX)
|
CMPXCHGL,L代表4个字节。该指令会把AX(累加器寄存器)中的内容(old)和第二个操作数(0(BX))中的内容(ptr所指向的数据)比较。如果相等,则把第一个操作数(CX)中的内容(new)赋值给第二个操作数(0(BX))。
这里,SETEQ 与CMPXCHGL是配合使用的,如果CMPXCHGL中比较结果是相等的,则设置ret(即函数原型中的swapped)为1,不等则设置为0。RET代表函数返回。
Mutex
其实Mutex的底层实现也是依赖原子操作中的CAS实现的,原子操作的atomic包相当于是sync包里的那些同步原语的实现依赖。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// Outlined slow path to allow inlining the fast path.
// To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock.
m.unlockSlow(new)
}
}
|
参考文章:
二、atomic.Value
在 Go 语言标准库中,sync/atomic包将底层硬件提供的原子操作封装成了 Go 的函数。但这些操作只支持几种基本数据类型,因此为了扩大原子操作的适用范围,Go 语言在 1.4 版本的时候向sync/atomic包中添加了一个新的类型Value。此类型的值相当于一个容器,可以被用来“原子地"存储(Store)和加载(Load)任意类型的值。
原子性
一个或者多个操作在 CPU 执行的过程中不被中断的特性,称为原子性(atomicity)。这些操作对外表现成一个不可分割的整体,他们要么都执行,要么都不执行,外界不会看到他们只执行到一半的状态。而在现实世界中,CPU 不可能不中断的执行一系列操作,但如果我们在执行多个操作时,能让他们的中间状态对外不可见,那我们就可以宣称他们拥有了"不可分割”的原子性。
由下面的问题引入 atomic.Value.
问 :一条普通的赋值语句,是原子操作吗?
有些朋友可能不知道,在 Go(甚至是大部分语言)中,一条普通的赋值语句其实不是一个原子操作。例如,在32位机器上写int64类型的变量就会有中间状态,因为它会被拆成两次写操作(MOV)——写低 32 位和写高 32 位,如下图所示:
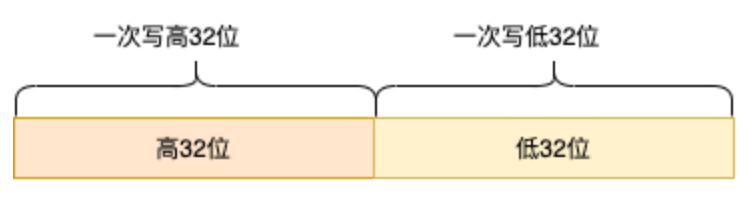
如果一个线程刚写完低32位,还没来得及写高32位时,另一个线程读取了这个变量,那它得到的就是一个毫无逻辑的中间变量,这很有可能使我们的程序出现诡异的 Bug。
这还只是一个基础类型,如果我们对一个结构体进行赋值,那它出现并发问题的概率就更高了。很可能写线程刚写完一小半的字段,读线程就来读取这个变量,那么就只能读到仅修改了一部分的值。这显然破坏了变量的完整性,读出来的值也是完全错误的。
面对这种多线程下变量的读写问题,我们的主角——atomic.Value登场了,它使得我们可以不依赖于不保证兼容性的unsafe.Pointer类型,同时又能将任意数据类型的读写操作封装成原子性操作(让中间状态对外不可见)。
使用方法
atomic.Value类型对外暴露的方法就两个:
v.Store(c) - 写操作,将原始的变量c存放到一个atomic.Value类型的v里。c = v.Load() - 读操作,从线程安全的v中读取上一步存放的内容。
使用时,只需**将需要并发保护的变量读取和赋值操作用Load()和Store()**代替就行了。
举例一个简单的使用场景:应用程序定期的从外界获取最新的配置信息,然后更改自己内存中维护的配置变量。工作线程根据最新的配置来处理请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
package main
import (
"sync/atomic"
"time"
)
func loadConfig() map[string]string {
// 从数据库或者文件系统中读取配置信息,然后以map的形式存放在内存里
return make(map[string]string)
}
func requests() chan int {
// 将从外界中接受到的请求放入到channel里
return make(chan int)
}
func main() {
// config变量用来存放该服务的配置信息
var config atomic.Value
// 初始化时从别的地方加载配置文件,并存到config变量里
config.Store(loadConfig())
go func() {
// 每10秒钟定时拉取最新的配置信息,并且更新到config变量里
for {
time.Sleep(10 * time.Second)
// 对应于赋值操作 config = loadConfig()
config.Store(loadConfig())
}
}()
// 创建工作线程,每个工作线程都会根据它所读取到的最新的配置信息来处理请求
for i := 0; i < 10; i++ {
go func() {
for r := range requests() {
// 对应于取值操作 c := config
// 由于Load()返回的是一个interface{}类型,所以我们要先强制转换一下
c := config.Load().(map[string]string)
// 这里是根据配置信息处理请求的逻辑...
_, _ = r, c
}
}()
}
}
|
实现原理
数据结构
atomic.Value被设计用来存储任意类型的数据,所以它内部的字段是一个any类型(也就是interface{}),非常的简单粗暴。
1
2
3
|
type Value struct {
v any
}
|
除了Value外,这个文件里还定义了一个ifaceWords类型,这其实是一个空interface (interface{})的内部表示格式(参见runtime/runtime2.go中eface的定义)。它的作用是将interface{}类型分解,得到其中的两个字段。
1
2
3
4
5
|
// ifaceWords is interface{} internal representation.
type ifaceWords struct {
typ unsafe.Pointer
data unsafe.Pointer
}
|
unsafe.Pointer
在介绍写入之前,我们先来看一下 Go 语言内部的unsafe.Pointer类型。
出于安全考虑,Go 语言并不支持直接操作内存,但它的标准库中又提供一种*不安全(不保证向后兼容性)*的指针类型unsafe.Pointer,让程序可以灵活的操作内存。
unsafe.Pointer的特别之处在于:它可以绕过 Go 语言类型系统的检查,与任意的指针类型互相转换。也就是说,如果两种类型具有相同的内存结构(layout),我们可以将unsafe.Pointer当做桥梁,让这两种类型的指针相互转换,从而实现同一份内存拥有两种不同的解读方式。
比如说,[]byte和string其实内部的存储结构都是一样的,但 Go 语言的类型系统禁止他俩互换。他们在运行时类型分别表示为reflect.SliceHeader和reflect.StringHeader:
1
2
3
4
5
6
7
8
9
10
|
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
type StringHeader struct {
Data uintptr
Len int
}
|
如果借助unsafe.Pointer,我们就可以实现在零拷贝的情况下,将[]byte数组直接转换成string类型。
1
2
3
4
5
6
7
|
func main() {
bytes := []byte("hello")
fmt.Println(bytes) // 输出 [104 101 108 108 111]
p := unsafe.Pointer(&bytes) // 强制转换成unsafe.Pointer,编译器不会报错
str := *(*string)(p) // 然后强制转换成string类型的指针,再将这个指针的值当做string类型取出来
fmt.Println(str) // 输出 "hello"
}
|
写入(Store)操作
知道了unsafe.Pointer的作用,就可以来看代码了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
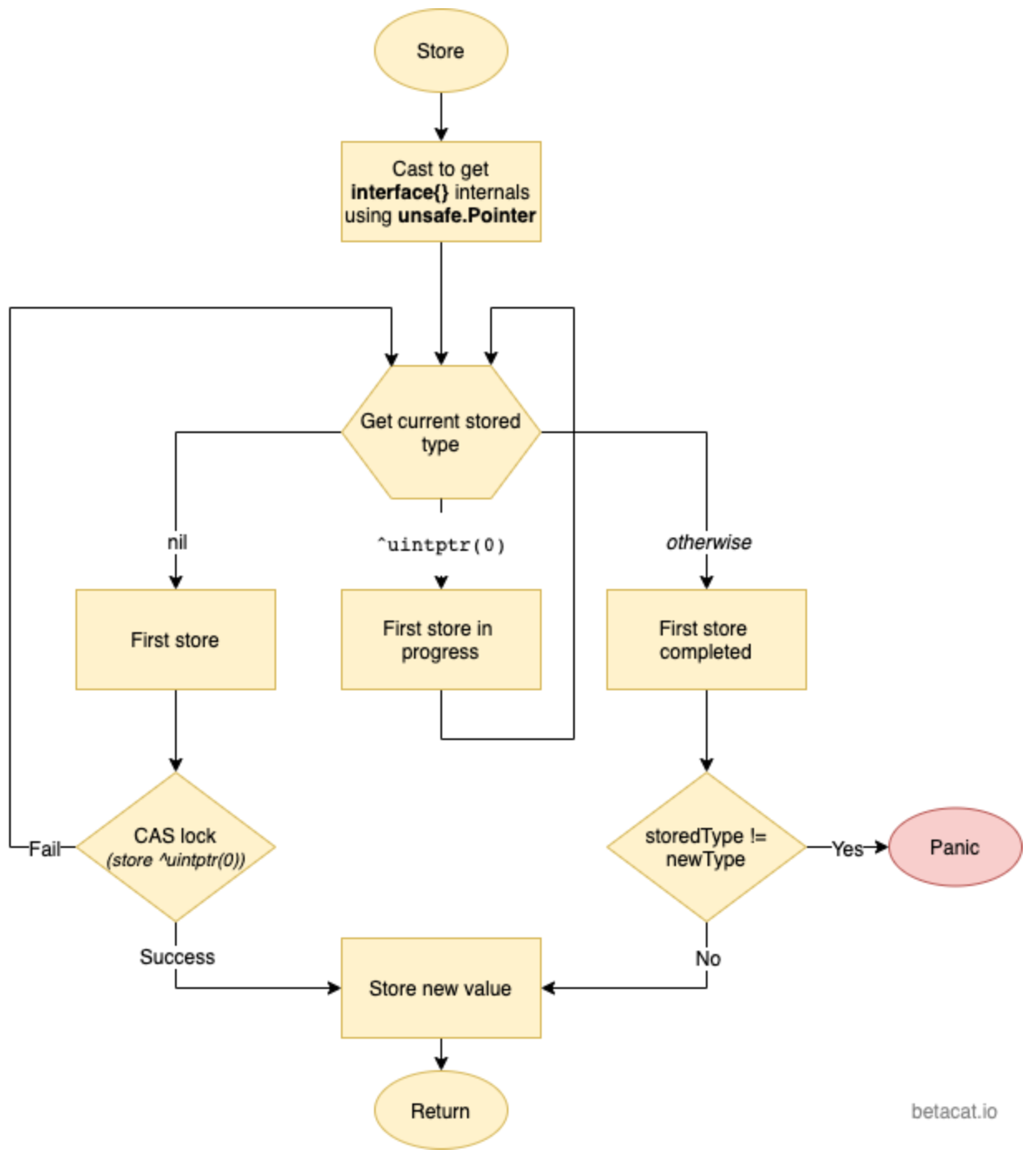
func (v *Value) Store(val any) {
if val == nil {
panic("sync/atomic: store of nil value into Value")
}
vp := (*ifaceWords)(unsafe.Pointer(v))
vlp := (*ifaceWords)(unsafe.Pointer(&val))
for {
typ := LoadPointer(&vp.typ)
if typ == nil {
// Attempt to start first store.
// Disable preemption so that other goroutines can use
// active spin wait to wait for completion.
runtime_procPin()
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(&firstStoreInProgress)) {
runtime_procUnpin()
continue
}
// Complete first store.
StorePointer(&vp.data, vlp.data)
StorePointer(&vp.typ, vlp.typ)
runtime_procUnpin()
return
}
if typ == unsafe.Pointer(&firstStoreInProgress) {
// First store in progress. Wait.
// Since we disable preemption around the first store,
// we can wait with active spinning.
continue
}
// First store completed. Check type and overwrite data.
if typ != vlp.typ {
panic("sync/atomic: store of inconsistently typed value into Value")
}
StorePointer(&vp.data, vlp.data)
return
}
}
|
大概的逻辑:
-
第 5~6 行 - 通过unsafe.Pointer将现有的和要写入的值分别转成ifaceWords类型,这样我们下一步就可以得到这两个interface{}的原始类型(typ)和真正的值(data)。
-
从第 7 行开始就是一个无限 for 循环。配合CompareAndSwap使用,可以达到乐观锁的功效。
-
第 8 行,我们可以通过LoadPointer这个原子操作拿到当前Value中存储的类型。下面根据这个类型的不同,分3种情况处理:
-
第一次写入(第9~24行) - 一个Value实例被初始化后,它的typ字段会被设置为指针的零值 nil,所以第 9 行先判断,如果typ是 nil,那就证明这个Value还未被写入过数据。那之后就是一段初始写入的操作:
runtime_procPin()是runtime中的一段函数,具体的功能我不是特别清楚,也没有找到相关的文档。这里猜测一下,一方面它禁止了调度器对当前 goroutine 的抢占(preemption),使得它在执行当前逻辑的时候不被打断,以便可以尽快地完成工作,因为别人一直在等待它。另一方面,在禁止抢占期间,GC 线程也无法被启用,这样可以防止 GC 线程看到一个莫名其妙的指向^uintptr(0)的类型(这是赋值过程中的中间状态)。- 使用
CAS操作,先尝试将typ设置为^uintptr(0)这个中间状态。如果失败,则证明已经有别的线程抢先完成了赋值操作,那它就解除抢占锁,然后重新回到 for 循环第一步。
- 如果设置成功,那证明当前线程抢到了这个"乐观锁",它可以安全的把
v设为传入的新值了(19~23行)。注意,这里是先写data字段,然后再写typ字段。因为我们是以typ字段的值作为写入完成与否的判断依据的。
-
第一次写入还未完成(第25~30行)- 如果看到 typ字段还是^uintptr(0)这个中间类型,证明刚刚的第一次写入还没有完成,所以它会继续循环,“忙等"到第一次写入完成。
-
第一次写入已完成(第31行及之后) - 首先检查上一次写入的类型与这一次要写入的类型是否一致,如果不一致则抛出异常。反之,则直接把这一次要写入的值写入到data字段。
这个逻辑的主要思想就是:为了完成多个字段的原子性写入,我们可以抓住其中的一个字段,以它的状态来标志整个原子写入的状态。
读取(Load)操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// Load returns the value set by the most recent Store.
// It returns nil if there has been no call to Store for this Value.
func (v *Value) Load() (val any) {
vp := (*ifaceWords)(unsafe.Pointer(v))
typ := LoadPointer(&vp.typ)
if typ == nil || typ == unsafe.Pointer(&firstStoreInProgress) {
// First store not yet completed.
return nil
}
data := LoadPointer(&vp.data)
vlp := (*ifaceWords)(unsafe.Pointer(&val))
vlp.typ = typ
vlp.data = data
return
}
|
读取相对就简单很多了,它有两个分支:
- 如果当前的
typ是 nil 或者^uintptr(0),那就证明第一次写入还没有开始,或者还没完成,那就直接返回 nil (不对外暴露中间状态)。
- 否则,根据当前看到的
typ和data构造出一个新的interface{}返回出去。
参考文章:
面试题
问:原子操作和锁的区别?⭐
- 原子操作由底层硬件支持,而锁则由操作系统的调度器实现;
- 锁应当用来保护一段逻辑,原子操作用来对一个变量的更新保护,如果要更新的是一个复合对象,则应当使用
atomic.Value封装好的实现。
问:CAS 底层实现原理?⭐
从思想方面,从汇编代码方面回答。