Go浅析-性能分析
[toc]
一、概述
在 Go 语言中,主要关注的程序运行情况包括以下几种:
CPU profile:报告程序的 CPU 使用情况,按照一定频率去采集应用程序在 CPU 和寄存器上面的数据;Memory Profile(Heap Profile):报告程序的内存使用情况;Block Profile:报告导致阻塞的同步原语的情况,可以用来分析和查找锁的性能瓶颈;Goroutine Profile:报告 goroutines 的使用情况,有哪些 goroutine,它们的调用关系是怎样的。
benchmark(基准测试) 可以度量某个函数或方法的性能,也就是说,如果我们知道性能的瓶颈点在哪里,benchmark 是一个非常好的方式。但是面对一个未知的程序,如何去分析这个程序的性能,并找到瓶颈点呢?
pprof 就是用来解决这个问题的。pprof 包含两部分:
- 编译到程序中的
runtime/pprof包 - 性能剖析工具
go tool pprof
针对不同场景,应采用不同的分析方法:
- 工具类应用:执行完任务就结束退出。可以使用
runtime/pprof库; - 服务型应用:应用需要一直运行,比如 web 应用或者
gRPC服务。可以使用net/http/pprof库,能够在应用提供 HTTP 服务时进行分析。
二、性能分析类型
2.1 CPU 性能分析
CPU 性能分析(CPU profiling) 是最常见的性能分析类型。
主要思想:一个函数在性能分析数据中出现的次数越多,说明执行该函数的代码路径(code path)花费的时间占总运行时间的比重越大。
主要原理:启动 CPU 分析时,运行时(runtime) 将每隔 10ms 中断一次,记录此时正在运行的协程(goroutines) 的堆栈信息。程序运行结束后,可以分析记录的数据找到最热代码路径(hottest code paths)。
2.2 内存性能分析
内存性能分析(Memory profiling) 记录堆内存分配时的堆栈信息,忽略栈内存分配信息。
内存性能分析启用时,默认每1000次采样1次,这个比例是可以调整的。因为内存性能分析是基于采样的,因此基于内存分析数据来判断程序所有的内存使用情况是很困难的。
2.3 阻塞性能分析
阻塞性能分析(block profiling) 是 Go 特有的。
阻塞性能分析用来记录一个协程等待一个共享资源花费的时间。在判断程序的并发瓶颈时会很有用。阻塞的场景包括:
- 在没有缓冲区的信道上发送或接收数据。
- 从空的信道上接收数据,或发送数据到满的信道上。
- 尝试获得一个已经被其他协程锁住的排它锁。
一般情况下,当所有的 CPU 和内存瓶颈解决后,才会考虑这一类分析。
2.4 锁性能分析
锁性能分析(mutex profiling) 与阻塞分析类似,但专注于因为锁竞争导致的等待或延时。
三、CPU 性能分析
记录性能数据会对程序的性能产生影响,建议一次只记录一类数据。
3.1 生成 profile
Go 的运行时性能分析接口都位于 runtime/pprof 包中。只需要调用 runtime/pprof 库即可得到我们想要的数据。
假设我们实现了这么一个程序,随机生成了 5 组数据,并且使用冒泡排序法排序。
|
|
如果我们想度量这个应用程序的 CPU 性能数据,只需要在 main 函数中添加几行代码即可:
|
|
3.2 数据分析
|
|
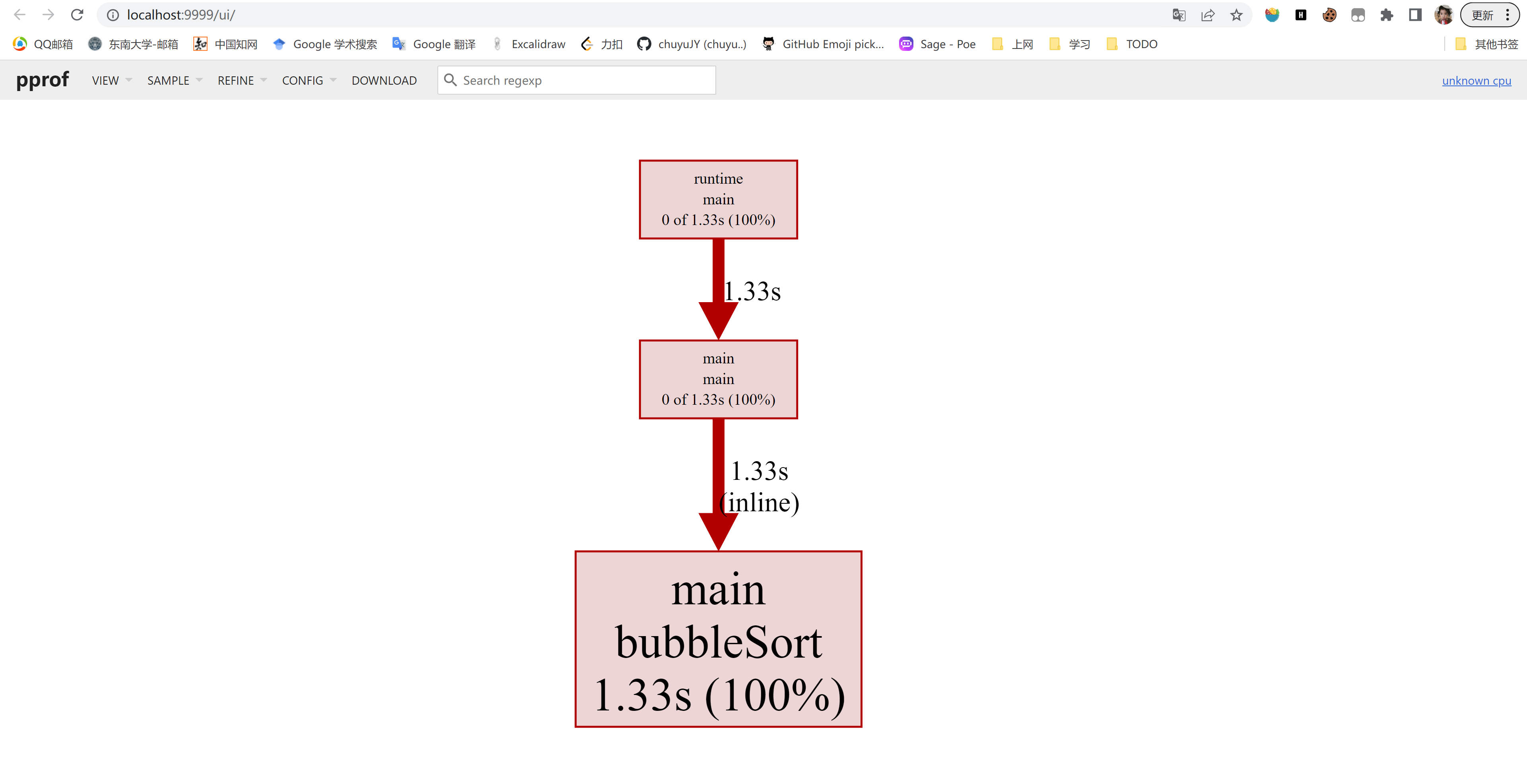
然后访问:localhost/:9999 即可。
|
|
|
|
可以看到 main.bubbleSort 是消耗 CPU 最多的函数。
还可以按照 cum (累计消耗)排序。通过 help 查看所有的命令。
四、内存性能分析
4.1 生成 profile
假设我们实现了这么一个程序,生成长度为 N 的随机字符串,拼接在一起。
使用一个易用性更强的库 pkg/profile 来采集性能数据,pkg/profile 封装了 runtime/pprof 的接口,使用起来更简单。
|
|
参考文章: