[toc]
一、Gin 框架
问:为什么需要 Web框架?
net/http提供了基础的Web功能,即监听端口,映射静态路由,解析HTTP报文。一个实例:
1
2
3
4
5
6
7
8
9
|
func main() {
http.HandleFunc("/", handler)
http.HandleFunc("/count", counter)
log.Fatal(http.ListenAndServe("localhost:8000", nil))
}
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "URL.Path = %q\n", r.URL.Path)
}
|
但一些Web开发中简单的需求并不支持,需要手工实现:
- 动态路由:例如
hello/:name,hello/*这类的规则。
- 鉴权:没有分组/统一鉴权的能力,需要在每个路由映射的handler中实现。
- 模板:没有统一简化的HTML机制。
统一入口
1
2
3
4
5
6
7
|
package http
type Handler interface {
ServeHTTP(w ResponseWriter, r *Request)
}
func ListenAndServe(address string, h Handler) error
|
其实就是,实现Handler接口,拦截所有的请求到咱们自己的处理逻辑。
解释一下:你可以看这点代码:http.ListenAndServe("localhost:8000", nil),后面是nil,其实http库会自动给个默认的DefaultServeMux,也就把所有的请求用这个处理了,所以第一件事就是拦截掉所有的请求!
==路由映射==(动态路由有点问题吧,测试一下)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func main() {
r := gee.New()
r.GET("/", func(w http.ResponseWriter, req *http.Request) {
fmt.Fprintf(w, "URL.Path = %q\n", req.URL.Path)
})
r.GET("/hello", func(w http.ResponseWriter, req *http.Request) {
for k, v := range req.Header {
fmt.Fprintf(w, "Header[%q] = %q\n", k, v)
}
})
r.Run(":9999")
}
|
其实就是,把路由地址和对应的处理函数,存起来。
解释一下:这里最简单的办法是啥?不就是在r里边整个哈希表,把路由和处理函数分别当成key和val嘛?但是哈希表有一个弊端:只能支持静态路由。
支持动态路由,有很多方法:
这里实现动态路由具备两个功能:
- 参数匹配
:。例如 /p/:lang/doc,可以匹配 /p/c/doc 和 /p/go/doc;
- 通配
*。例如 /static/*filepath,可以匹配/static/fav.ico,也可以匹配/static/js/jQuery.js,这种模式常用于静态服务器,能够递归地匹配子路径。
实现前缀树后,可以在router中对每一种类型的方法都维护一颗Trie。
对于动态路由传递的参数,可以放在Context中的Param里。
设计Context
设计上下文(Context),封装 Request 和 Response,提供对 JSON、HTML 等返回类型的支持。
必要性:
- 对Web服务来说,无非是根据请求
*http.Request,构造响应http.ResponseWriter。但是这两个对象提供的接口粒度太细,比如我们要构造一个完整的响应,需要考虑消息头(Header)和消息体(Body),而 Header 包含了状态码(StatusCode),消息类型(ContentType)等几乎每次请求都需要设置的信息。因此,如果不进行有效的封装,那么框架的用户将需要写大量重复,繁杂的代码,而且容易出错。针对常用场景,能够高效地构造出 HTTP 响应是一个好的框架必须考虑的点。
示例:
封装前
1
2
3
4
5
6
7
8
9
10
|
obj = map[string]interface{}{
"name": "geektutu",
"password": "1234",
}
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusOK)
encoder := json.NewEncoder(w)
if err := encoder.Encode(obj); err != nil {
http.Error(w, err.Error(), 500)
}
|
VS 封装后:
1
2
3
4
|
c.JSON(http.StatusOK, gee.H{
"username": c.PostForm("username"),
"password": c.PostForm("password"),
})
|
- Context 还可以支撑其他功能。比如:
- **动态路由的参数:**将来解析动态路由
/hello/:name,参数:name的值放在哪呢?
- **中间件的参数与结果:**框架需要支持中间件,那中间件产生的信息放在哪呢?
Context 随着每一个请求的出现而产生,请求的结束而销毁,和当前请求强相关的信息都应由 Context 承载。 Context 就像一次会话的百宝箱,可以找到任何东西。
- 提供了访问Query和PostForm参数的方法;
- 提供了快速构造String/Data/JSON/HTML响应的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
package gee
import (
"encoding/json"
"fmt"
"net/http"
)
type H map[string]interface{}
type Context struct {
// origin objects
W http.ResponseWriter
Req *http.Request
// req info
Path string // 其实就是 pattern
Method string // 请求方法
Params map[string]string // 存储Path传递的参数
// resp info
StatusCode int // 响应码
// middleware
handlers []HandlerFunc // 存储中间件
index int // 记录当前执行到第几个中间件
// engine pointer
engine *Engine
}
func NewContext(w http.ResponseWriter, req *http.Request) *Context {
return &Context{
W: w,
Req: req,
Path: req.URL.Path,
Method: req.Method,
index: -1,
}
}
// 获取传递的参数
func (c *Context) Param(key string) string {
return c.Params[key]
}
// 获取Form的数据
func (c *Context) PostForm(key string) string {
return c.Req.FormValue(key)
}
// 获取Query的数据
func (c *Context) Query(key string) string {
return c.Req.URL.Query().Get(key)
}
func (c *Context) Status(code int) {
c.StatusCode = code
c.W.WriteHeader(code)
}
func (c *Context) SetHeader(key string, value string) {
c.W.Header().Set(key, value)
}
func (c *Context) String(code int, format string, values ...interface{}) {
c.SetHeader("Content-Type", "text/plain")
c.Status(code)
c.W.Write([]byte(fmt.Sprintf(format, values...)))
}
func (c *Context) Data(code int, data []byte) {
c.Status(code)
c.W.Write(data)
}
func (c *Context) JSON(code int, obj interface{}) {
c.SetHeader("Content-Type", "application/json")
c.Status(code)
encoder := json.NewEncoder(c.W)
if err := encoder.Encode(obj); err != nil {
http.Error(c.W, err.Error(), 500)
}
}
func (c *Context) HTML(code int, name string, data interface{}) {
c.SetHeader("Content-Type", "text/html")
c.Status(code)
if err := c.engine.htmlTemplates.ExecuteTemplate(c.W, name, data); err != nil {
c.String(500, err.Error())
}
}
// middleware
func (c *Context) Next() {
c.index++
s := len(c.handlers)
for c.index < s {
c.handlers[c.index](c)
c.index++
}
}
|
==分组控制==(未)
所谓分组,是指路由的分组。如果没有路由分组,我们需要针对每一个路由进行单独控制。但是真实的业务场景中,往往某一组路由需要相似的处理或相同的中间件。例如:
- 以
/post开头的路由匿名可访问。
- 以
/admin开头的路由需要鉴权。
- 以
/api开头的路由是 RESTful 接口,可以对接第三方平台,需要三方平台鉴权。
此处实现的分组控制是以前缀进行分组的,并且支持嵌套分组,如/post是一个分组,/post/a和/post/b可以是该分组下的子分组。作用在/post分组上的中间件(middleware),也都会作用在子分组,子分组还可以应用自己特有的中间件。
==中间件==
中间件的设计主要考虑两点:
- **插入点设置在哪?**因为要支持用户自己的功能插入框架,所以插入位置就很关键,太底层逻辑就会很复杂,太上层了就会跟用户直接调用函数没区别了;
- **输入参数是啥?**中间件的输入,决定了扩展能力。暴露的参数太少,用户发挥空间有限。
此处是这样设计的:
==模板Template==(未)
比如,Web框架支持服务端渲染的场景。
==错误恢复==(未)
添加了非常简单的错误处理中间件:在此类错误发生时,向用户返回 Internal Server Error,并且在日志中打印必要的错误信息,方便进行错误定位。
二、分布式缓存框架
仿照 groupCache 实现,最大的特点是没有删除、更新接口,只有Get接口。
问:为什么要设计分布式缓存机制?
最简单的缓存就是用哈希表。但是会有以下问题:
- 内存不够了咋办,需要实现一个合理的缓存淘汰策略;
- 全局哈希表存在访问冲突,需要加锁,降低效率;
- 单机性能可能不够,单点故障的成本太高,分布式缓存可以增强系统鲁棒性。
- …
问:支持那些特性?
- 单机缓存和基于 HTTP 的分布式缓存;
- 最近最少访问(Least Recently Used, LRU) 缓存策略;
- 使用 Go 锁机制防止缓存击穿;
- 使用一致性哈希选择节点,实现负载均衡;
- 使用 protobuf 优化节点间二进制通信;
- 。。。
缓存策略
缓存肯定不能无限大,超过设置容量时需要有合理的淘汰策略。
常见的缓存策略:
- FIFO:队列嘛,先进先出,显然很不合理;
- LFU:按照使用次数排序,淘汰最少使用的;
- LRU:最近最少使用;
问:缓存大小是如何表示的?
使用[]byte存储数据,其长度len()就是占用多少Byte。
问:数据存放格式?⭐
缓存Cache由以下字段组成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type Cache struct {
MaxEntries int
OnEvicted func(key Key, value interface{})
ll *list.List // 真正存储 entry 指针的地方
cache map[interface{}]*list.Element // 存储 key - entry,用于快速找到 entry
}
type Key interface{}
type entry struct {
key Key
value interface{}
}
|
当要存储一对 key-value时,首先转换成 entry 对象,理论上 key 和 value 都是 interface{},也就是支持所有类型。
插入时,若key之前不存在,就是插入;若已存在,就是更新:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// Add adds a value to the cache.
func (c *Cache) Add(key Key, value interface{}) {
if c.cache == nil {
c.cache = make(map[interface{}]*list.Element)
c.ll = list.New()
}
if ee, ok := c.cache[key]; ok {
c.ll.MoveToFront(ee)
ee.Value.(*entry).value = value
return
}
ele := c.ll.PushFront(&entry{key, value}) // ll 中存储的其实是 entry 对象的指针
c.cache[key] = ele
if c.MaxEntries != 0 && c.ll.Len() > c.MaxEntries {
c.RemoveOldest()
}
}
|
问:数据支持哪些操作?
只支持 Get。
用户使用时,需要实现以下:
- 初始化的时候,就需要明确当 key miss 的时候,怎么获取到内容的手段,把这个手段配置好是前提;
- get 调用的时候,当 key miss 的时候,就会调用初始化的获取手段来获取数据,如果 hit 的话,那么就直接返回了。
问:这种只能 get ,不能更新 key 的缓存有啥用?有什么适用场景?
比如你缓存一些静态文件,用文件 md5 作为 key,value 就是文件。这种场景就很适合用 groupcache 这种缓存,因为 key 对应的 value 不需要变。
参考文章:
单机并发缓存
并发设计多协程,所以肯定需要一把互斥锁。
问:单机并发缓存是如何实现的?
在lru外再封装一层,主要数据结构:
1
2
3
4
5
|
type cache struct {
mu sync.Mutex // 支持并发, 必须有锁
lru *lru.Cache
cacheBytes int64 // 缓存容量 Byte
}
|
为了区分不同类型的缓存,设置Group,负责与用户交互,控制缓存值存储和获取的流程:
1
2
3
4
5
6
7
8
|
/*
是
接收 key --> 检查是否被缓存 -----> 返回缓存值 ⑴
| 否 是
|-----> 是否应当从远程节点获取 -----> 与远程节点交互 --> 返回缓存值 ⑵
| 否
|-----> 调用`回调函数`,获取值并添加到缓存 --> 返回缓存值 ⑶
*/
|
问:若缓存不存在,怎么获取呢?
分为从远程节点获取和**调用用户逻辑(回调函数)**获取。
因为数据怎么获得、获得的来源是哪,应该是框架的用户需要考虑的,所以只需要开放一个回调函数接口即可。
**用户需要自定义一个GetterFunc类型的函数。**当缓存未命中时,就会调用此函数获取数据,获取之后会调用cache.put()更新缓存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// Getter 未命中时从数据源获取数据
type Getter interface {
Get(key string) ([]byte, error) // 回调函数
}
// 函数类型实现某一个接口,称之为接口型函数。
// 方便使用者在调用时既能够传入函数作为参数,也能够传入实现了该接口的结构体作为参数。
// 是一个将函数转换为接口的技巧
type GetterFunc func(key string) ([]byte, error)
// Get 实现Getter接口
func (f GetterFunc) Get(key string) ([]byte, error) {
return f(key)
}
|
一致性哈希
问:一致性哈希原理?有啥用?
一致性哈希算法将 key 映射到 2^32^ 的空间中,将这个数字首尾相连,形成一个环。
- 计算节点/机器(通常使用节点的名称、编号和 IP 地址)的哈希值,放置在环上。
- 计算 key 的哈希值,放置在环上,顺时针寻找到的第一个节点,就是应选取的节点/机器。
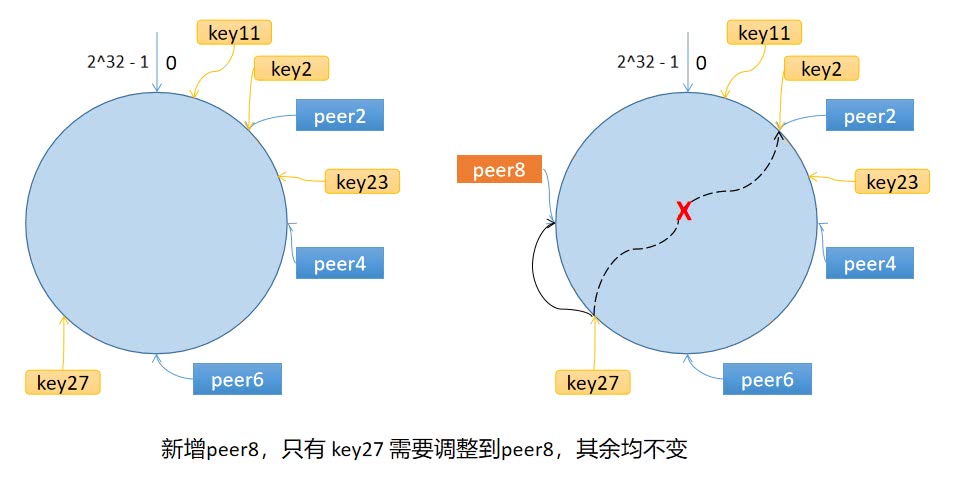
环上有 peer2,peer4,peer6 三个节点,key11,key2,key27 均映射到 peer2,key23 映射到 peer4。此时,如果新增节点/机器 peer8,假设它新增位置如图所示,那么只有 key27 从 peer2 调整到 peer8,其余的映射均没有发生改变。
也就是说,一致性哈希算法,在新增/删除节点时,只需要重新定位该节点附近的一小部分数据,而不需要重新定位所有的节点。
问:怎么解决数据倾斜问题?
==数据倾斜是什么?==
**如果服务器的节点过少,容易引起 key 的倾斜。**例如上面例子中的 peer2,peer4,peer6 分布在环的上半部分,下半部分是空的。那么映射到环下半部分的 key 都会被分配给 peer2,key 过度向 peer2 倾斜,缓存节点间负载不均。
==怎么解决?==
**引入了虚拟节点:**一个真实节点对应多个虚拟节点。
假设 1 个真实节点对应 3 个虚拟节点,那么 peer1 对应的虚拟节点是 peer1-1、 peer1-2、 peer1-3(通常以添加编号的方式实现),其余节点也以相同的方式操作。
- 第一步,计算虚拟节点的 Hash 值,放置在环上。
- 第二步,计算 key 的 Hash 值,在环上顺时针寻找到应选取的虚拟节点,例如是 peer2-1,那么就对应真实节点 peer2。
**虚拟节点扩充了节点的数量,解决了节点较少的情况下数据容易倾斜的问题。**而且代价非常小,只需要增加一个字典(map)维护真实节点与虚拟节点的映射关系即可。
问:具体是如何实现的呢?
Go实现部分:https://geektutu.com/post/geecache-day4.html
就是:
1
2
3
4
5
6
7
8
|
type Hash func(data []byte) uint32
type Map struct {
hash Hash // 可更换用户自定义的哈希函数,默认为crc32.ChecksumIEE()
replicas int // 虚拟节点倍数,即一个真实节点对应replicas个虚拟节点
keys []int // 哈希环,存储每个节点的hash值
hashMap map[int]string // 节点哈希值 - 真实节点名称
}
|
1
2
3
4
5
6
7
8
9
10
|
func (m *Map) Add(keys ...string) { // keys是节点名称
for _, key := range keys {
for i := 0; i < m.replicas; i++ { // 每个真实节点都创建replicas个虚拟节点
hash := int(m.hash([]byte(strconv.Itoa(i) + key))) // 求 虚拟节点("i+key") 的哈希值
m.keys = append(m.keys, hash) // 加入哈希环
m.hashMap[hash] = key // 虚拟节点 - 真实节点
}
}
sort.Ints(m.keys) // 排序
}
|
1
2
3
4
5
6
7
8
9
10
11
|
func (m *Map) Get(key string) string { // key是查找键值对的建
if len(m.keys) == 0 {
return ""
}
hash := int(m.hash([]byte(key)))
// 二分查找
idx := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash // 在哈希环上查找所在的节点(真实/虚拟)
})
return m.hashMap[m.keys[idx%len(m.keys)]] // 根据节点值在hashMap中查找对应的真实节点
}
|
HTTP 分布式缓存
- 首先是服务端
服务端需要接受来自其他节点的请求:
- 约定访问路径格式为
/<basepath>/<groupname>/<key>,通过 groupname 得到 group 实例,再使用 group.Get(key) 获取缓存数据。
- 最终使用
w.Write() 将缓存值作为 httpResponse 的 body 返回。
- 客户端
客户端需要实现以下功能:
- 根据传入的 key 选择相应的缓存节点;
- 向指定的节点查找缓存值;
问:具体如何实现客户端?
- 客户端本地需要维护一个缓存节点池,将远程节点注册;
- 客户端要查找某key对应的值时,先从本地缓存节点池取出对应节点的地址;
- 然后发起请求从远程缓存节点得到缓存值;
- 若获取远程节点失败或未命中,则回退到从本地节点获取。
抽象出两个接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// HTTPPool 承载节点间 HTTP 通信的核心数据结构
type HTTPPool struct {
self string // 记录自己的地址,包括主机名/IP 和端口
basePath string // 节点间通讯地址的前缀,默认是 /_geecache/
mu sync.Mutex // 保护peers和httpGetters
peers *consistenthash.Map // 根据具体的 key 选择节点
httpGetters map[string]*httpGetter // 映射远程节点与对应的 httpGetter, 每一个远程节点对应一个 httpGetter
}
type PeerPicker interface {
PickPeer(key string) (peer PeerGetter, ok bool) // 根据传入的key,选择相应的节点
}
type PeerGetter interface {
Get(group string, key string) ([]byte, error) // 根据传入的key 和 选择的节点,查找缓存值
}
|
1
2
3
4
5
6
7
8
9
10
|
// 根据具体的 key,选择节点,返回节点对应的 HTTP 客户端
func (p *HTTPPool) PickPeer(key string) (PeerGetter, bool) {
p.mu.Lock()
defer p.mu.Unlock()
if peer := p.peers.Get(key); peer != "" && peer != p.self { // 似乎哈希环也存在于客户端
p.Log("Pick peer %s", peer)
return p.httpGetters[peer], true
}
return nil, false
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 实例化一致性哈希算法,并且添加传入的节点。
func (p *HTTPPool) Set(peers ...string) {
p.mu.Lock()
defer p.mu.Unlock()
p.peers = consistenthash.NewMap(defaultReplicas, nil)
p.peers.Add(peers...)
p.httpGetters = make(map[string]*httpGetter, len(peers))
for _, peer := range peers {
p.httpGetters[peer] = &httpGetter{
baseURL: peer + p.basePath,
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
// Get 向指定节点查找缓存值
func (h *httpGetter) Get(in *pb.Request, out *pb.Response) error {
u := fmt.Sprintf(
// baseURL 表示将要访问的远程节点的地址
// 例如 http://example.com/_geecache/
"%v%v/%v", h.baseURL, url.QueryEscape(in.GetGroup()), url.QueryEscape(in.GetKey()),
)
res, err := http.Get(u)
if err != nil {
return err
}
defer res.Body.Close()
if res.StatusCode != http.StatusOK {
return fmt.Errorf("server returned: %v", res.Status)
}
bytes, err := ioutil.ReadAll(res.Body)
if err != nil {
return fmt.Errorf("reading response body: %v", err)
}
if err = proto.Unmarshal(bytes, out); err != nil {
return fmt.Errorf("decoding response body: %v", err)
}
return nil
}
|
防止缓存击穿
缓存击穿,通常发生在,针对热点数据的大量访问同时到达,但缓存中的热点数据刚好失效,导致大量SQL请求砸向MySQL。
针对相同的Key,同一个节点若并发的发起 N 次请求,这是没有意义的。此处通过 singleFlight解决。
因为多个线程间并不需要消息传递,非常适合sync.WaitGroup。
过程:
- 一个线程在查询 key 之前,需要先检查该 key 是否已经有
call请求正在进行;
- 若有,则等待
wg.wait锁释放,此时其实已经得到了这个值,直接返回即可;
- 若无,则创建一个
call请求,在发起前,对这个call中的锁进行上锁,也就是阻塞查找该 key 的其他线程,在等到数据之后便会通知到其他线程;
1
2
3
4
5
6
7
8
9
10
11
12
|
// call 代表正在进行中,或已经结束的请求。每个 call 使用 sync.WaitGroup 锁避免重入。
type call struct {
wg sync.WaitGroup
val interface{}
err error
}
// Group 是 singleflight 的主数据结构,管理不同 key 的请求(call)。
type Group struct {
mu sync.Mutex // 锁
m map[string]*call // 管理不同 key 的 call请求
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// 针对相同的 key,无论 Do 被调用多少次,函数 fn 都只会被调用一次,等待 fn 调用结束了,返回返回值或错误。
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok { // 若本次的 key 已经有 call请求正在进行中
g.mu.Unlock()
c.wg.Wait() // 如果请求正在进行中,则等待
return c.val, c.err
}
c := new(call)
c.wg.Add(1) // 发起请求前加锁
g.m[key] = c // 添加到 g.m,表明 key 已经有对应的请求在处理
g.mu.Unlock()
c.val, c.err = fn() // 调用 fn,发起请求
c.wg.Done() // 请求结束
g.mu.Lock()
delete(g.m, key) // 更新 g.m
g.mu.Unlock()
return c.val, c.err
}
|
Protobuf 通信
目的:
- **使用 protobuf 的目的非常简单,为了获得更高的性能。**传输前使用 protobuf 编码,接收方再进行解码,可以显著地降低二进制传输的大小。
- 另外一方面,protobuf 可非常适合传输结构化数据,便于通信字段的扩展。
三、Orm 框架
问:ORM 框架有什么用?
ORM 框架相当于对象和数据库中间的一个桥梁,借助 ORM 可以避免写繁琐的 SQL 语言,仅仅通过操作具体的对象,就能够完成对关系型数据库的操作。
问:设计 ORM 框架,需要关注哪些问题呢?
- 如何屏蔽不同数据库之间的差异?
- 如何从对象映射到数据库中的表结构/记录?
- MySQL,PostgreSQL,SQLite 等数据库的 SQL 语句是有区别的,ORM 框架如何在开发者不感知的情况下适配多种数据库?
- 如何实现:对象的字段发生改变,数据库表结构能够自动更新,即支持数据库自动迁移(migrate)?
- 数据库支持的其他功能,如事务等,ORM 框架能实现哪些?
简单的增删查改使用 ORM 替代 SQL 语句是没有问题的,但是也有很多特性难以用 ORM 替代,比如复杂的多表关联查询,ORM 也可能支持,但是基于性能的考虑,开发者自己写 SQL 语句很可能更高效。
问:你的 ORM 框架都实现了点啥?
目前支持的特性有:
- 表的创建、删除、迁移。
- 记录的增删查改,查询条件的链式操作。
- 单一主键的设置(primary key)。
- 钩子(在创建/更新/删除/查找之前或之后)。
- 事务(transaction)。
- 数据库迁移。
为了轻量化,目前只支持轻量级数据库 SQLite。
问:项目结构是怎样的?各部分都实现了啥?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
.
|-- clause // 5. 生成sql语句
| |-- clause.go // 组合sql子句为完整句子
| `-- generator.go // 生成拼合用到的sql子句
|-- cmd
| |-- gee.db
| `-- main.go
|-- dialect // 3. 抽象出各个数据库差异的部分
| |-- dialect.go // Go的数据类型 转换成 数据库的数据类型
| `-- sqlite3.go // 这是个示例:sqlite3的数据类型转换。要支持其他数据库,还需要添加对应数据库的
|-- geeorm.go // 2. 与用户交互的入口:交互前的准备工作(比如连接/测试),交互后的收尾工作(关闭连接)
|-- schema // 4. 负责 对象 --> 表 的转换
| `-- schema.go // schema就是存放 要转换成的表 的信息
`-- session // 1. 用来和数据库交互
|-- hooks.go // 钩子
|-- raw.go // 直接调用 SQL 语句进行原生交互的部分
|-- record.go // 用户直接调用的增删查改接口
|-- record_test.go
|-- table.go // "表"的增删查
`-- transaction.go // 事务
|
表结构映射
问:怎么实现的从结构体对象到表的映射?
在schema.go中。
在数据库中创建一张表需要哪些要素呢?
- 表名(table name) —— 结构体名(struct name)
- 字段名和字段类型 —— 成员变量和类型。
- 额外的约束条件(例如非空、主键等) —— 成员变量的Tag(Go 语言通过 Tag 实现,Java、Python 等语言通过注解实现)
举一个实际的例子:
1
2
3
4
|
type User struct {
Name string `geeorm:"PRIMARY KEY"`
Age int
}
|
期望对应的 schema 语句:
1
|
CREATE TABLE `User` (`Name` text PRIMARY KEY, `Age` integer);
|
主要问题是:如何通过任意类型的指针,得到其对应的结构体的信息。
所以 ORM 框架的实现需要依赖大量的 Reflect 操作:
reflect.ValueOf() 获取接口对应的反射值。reflect.Indirect() 获取指针指向的对象的反射值。(reflect.Type).Name() 返回类名(字符串)。(reflect.Type).Field(i) 获取第 i 个成员变量。
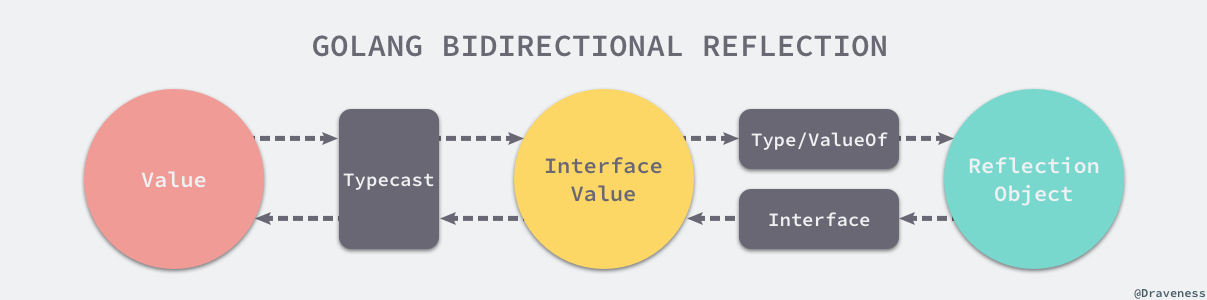
以上是一些基础知识。下面是映射流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 1. 要转换成的
// Schema 代表一张表
type Schema struct {
Model interface{} // 被映射的对象
Name string // 表名
Fields []*Field // 所有的字段信息
FieldNames []string // 所有的字段名
fieldMap map[string]*Field // 映射 [字段名: *Field]
}
// Field 字段的信息
type Field struct {
Name string // 字段名
Type string // 类型
Tag string // 约束条件
}
// 2. 转换对象,示例
type User struct {
name string `geeorm:"primary"`
age int `geeorm:"age"`
}
|
经过以下步骤,将User转换成数据库对象Schema:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// 1. 得到该结构体的类型元数据
modelType := reflect.Indirect(reflect.ValueOf(dest)).Type()
// 2. 建立Schema实例,也即映射到的表结构
schema := &Schema{
Model: dest,
Name: modelType.Name(), // 结构体的名称作为表名
fieldMap: make(map[string]*Field),
}
// 3. 得到该结构体所有的字段
for i := 0; i < modelType.NumField(); i++ {
p := modelType.Field(i)
field := &Field{
Name: p.Name,
Type: d.DataTypeOf(reflect.Indirect(reflect.New(p.Type))), // 会通过reflect.Kind转换类型
}
}
// 4. 在tag中寻找约束条件,比如主键之类的
if v, ok := p.Tag.Lookup("geeorm"); ok {
field.Tag = v
}
// 5. 往Schema中添加结构体的字段
schema.Fields = append(schema.Fields, field)
schema.FieldNames = append(schema.FieldNames, p.Name)
schema.fieldMap[p.Name] = field
|
然后就可以用 schema 中的信息,在数据库中建表:
1
2
3
4
5
6
7
8
9
10
11
|
// CreateTable 创建表
func (s *Session) CreateTable() error {
table := s.RefTable() // table就是schema,也就是表的信息
var columns []string
for _, field := range table.Fields {
columns = append(columns, fmt.Sprintf("%s %s %s", field.Name, field.Type, field.Tag))
}
desc := strings.Join(columns, ",")
_, err := s.Raw(fmt.Sprintf("CREATE TABLE %s (%s);", table.Name, desc)).Exec()
return err
}
|
插入、查询
问:如何实现带有条件的指令?
通常select和insert等指令都会带有条件,以这俩为例。
带有条件的语句,**需要多个子句进行拼合!**毕竟你不能构造出所有组合出来的语句。
用户主要通过clause.go,构造最终的sql语句:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
// Type SQL 语句种类
type Type int
const (
INSERT Type = iota
VALUES
SELECT
LIMIT
WHERE
ORDERBY
UPDATE
DELETE
COUNT
)
// Clause 组合 SQL 独立语句为完整句子
type Clause struct {
sql map[Type]string // SQL 语句
sqlVars map[Type][]interface{} // 参数
}
// Set 按照SQL语句的Name和参数, 得到子句
func (c *Clause) Set(name Type, vars ...interface{}) {
if c.sql == nil {
c.sql = make(map[Type]string)
c.sqlVars = make(map[Type][]interface{})
}
sql, vars := generators[name](vars...)
c.sql[name] = sql
c.sqlVars[name] = vars
}
// Build 按照传入子句类型的顺序,构造最终的SQL语句
func (c *Clause) Build(orders ...Type) (string, []interface{}) {
var sqls []string
var vars []interface{}
for _, order := range orders {
if sql, ok := c.sql[order]; ok {
sqls = append(sqls, sql)
vars = append(vars, c.sqlVars[order]...)
}
}
return strings.Join(sqls, " "), vars
}
|
所有构造 SQL 语句的方式都一致,分两步:
- 1)多次调用
clause.Set() 构造好每一个子句。
- 2)调用一次
clause.Build() 按照传入的顺序构造出最终的 SQL 语句。
构造完成后,调用 Raw().Exec() 方法执行。
问:select 咋实现多条件查询?
select 的构成通常包括很多查询条件,比如where、limit、‘group by’等:
1
2
3
4
5
|
SELECT col1, col2, ...
FROM table_name
WHERE [ conditions ]
GROUP BY col1
HAVING [ conditions ]
|
这是实现细节:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func _select(values ...interface{}) (string, []interface{}) {
// SELECT $fields FROM $tableName
tableName := values[0]
fields := strings.Join(values[1].([]string), ",")
return fmt.Sprintf("SELECT %v FROM %s", fields, tableName), []interface{}{}
}
func _limit(values ...interface{}) (string, []interface{}) {
// LIMIT $num
return "LIMIT ?", values
}
func _where(values ...interface{}) (string, []interface{}) {
// WHERE $desc
desc, vars := values[0], values[1:]
return fmt.Sprintf("WHERE %s", desc), vars
}
func _orderBy(values ...interface{}) (string, []interface{}) {
return fmt.Sprintf("ORDER BY %s", values[0]), []interface{}{}
}
|
构造带有多个条件的select的过程:
- 将不同的sql语句类型及其参数,如
select、limit、‘where’等,通过c.Set写入clause对象c;
- 调用
c.Build按照顺序构造最终的sql语句。
如:
1
2
3
4
5
6
7
8
|
var clause Clause
clause.Set(LIMIT, 3)
clause.Set(SELECT, "User", []string{"*"})
clause.Set(WHERE, "Name = ?", "Tom")
clause.Set(ORDERBY, "Age ASC")
sql, vars := clause.Build(SELECT, WHERE, ORDERBY, LIMIT)
// sql: SELECT * FROM User WHERE Name = ? ORDER BY Age ASC LIMIT ?
// vars: "Tom", 3
|
问:insert 咋实现多行插入?
insert 对应的 SQL 语句一般是这样的:
1
2
3
4
|
INSERT INTO table_name(col1, col2, col3, ...) VALUES
(A1, A2, A3, ...),
(B1, B2, B3, ...),
...
|
orm框架期望insert的调用方法为:
1
2
3
4
|
s := geeorm.NewEngine("sqlite3", "gee.db").NewSession()
u1 := &User{Name: "Tom", Age: 18}
u2 := &User{Name: "Sam", Age: 25}
s.Insert(u1, u2, ...)
|
实现细节:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// Insert 插入 values 到 sql
func (s *Session) Insert(values ...interface{}) (int64, error) {
recordValues := make([]interface{}, 0)
for _, value := range values { // 这里写的其实不好,插入对象其实要属于同一个表中
table := s.Model(value).RefTable() // 获取表的结构
s.clause.Set(clause.INSERT, table.Name, table.FieldNames) // 构造插入语句前半段, 按理来说只需要构造一次
recordValues = append(recordValues, table.RecordValues(value)) // 得到每个对象内的参数值
}
s.clause.Set(clause.VALUES, recordValues...)
sql, vars := s.clause.Build(clause.INSERT, clause.VALUES) // 对同一个表,一次性插入多个对象
result, err := s.Raw(sql, vars...).Exec()
if err != nil {
return 0, err
}
return result.RowsAffected()
}
|
一次性向同一张表插入多行:
- 拿到其中一个对象的结构体类型元数据,构造insert语句的前半段;
- 分别解析每个对象,获取相应字段的值,并构建成"( , , ,)“形式,将这些对象的值用
,连接,得到values语句;
- 调用build语句,组合这两个类型(
insert、values)的子语句,然后执行。
问:你的查询操作是怎么实现的?这里要回答Find,也就是嵌套了Insert的
实现如下功能:换入一个Slice指针,将查询的结果保存在Slice中。
1
2
3
|
s := geeorm.NewEngine("sqlite3", "gee.db").NewSession()
var users []User
s.Find(&users); // 取出 User 表中的所有行,并存储到 User 对象Slice
|
你想,大体其实就分两步:
- 从数据库得到行信息;
- 通过展开的行信息,构建出 User 对象,存到 Slice 即可。
具体的实现过程就有点复杂了:
- 首先要构造出从数据库对应表中的查询语句:
- 得到对象的类型元数据 destType,表的结构;
- 通过 s.Raw().QueryRows() 得到所有行;
- 遍历每一行记录,利用反射创建
destType 的实例 dest,将 dest 的所有字段平铺开,构造切片 values;
- 调用
rows.Scan() 将该行记录每一列的值依次赋值给 values 中的每一个字段;
- 将
dest 添加到切片 destSlice 中,循环直到所有的记录都添加到切片 destSlice 中。
因为 Find() 的参数就是切片的地址,所以,执行完Find(),该切片的内容也会得到改变~
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// Find 获取 values表 中所有对象, values 是对象类型的切片地址
func (s *Session) Find(values interface{}) error {
destSlice := reflect.Indirect(reflect.ValueOf(values))
destType := destSlice.Type().Elem() // 切片包含的元素的type
table := s.Model(reflect.New(destType).Elem().Interface()).RefTable()
s.clause.Set(clause.SELECT, table.Name, table.FieldNames)
sql, vars := s.clause.Build(clause.SELECT, clause.WHERE, clause.ORDERBY, clause.LIMIT)
rows, err := s.Raw(sql, vars...).QueryRows()
if err != nil {
return err
}
for rows.Next() {
dest := reflect.New(destType).Elem() // 利用反射 创建 destType 的实例 dest
var values []interface{}
for _, name := range table.FieldNames {
values = append(values, dest.FieldByName(name).Addr().Interface())
}
if err := rows.Scan(values...); err != nil {
return err
} // 调用 rows.Scan() 将该行记录每一列的值依次赋值给 values 中的每一个字段
destSlice.Set(reflect.Append(destSlice, dest)) // 向切片中添加元素
}
return rows.Close()
}
|
链式操作
问:什么是链式调用?
链式调用:某个对象调用某个方法后,将该对象的引用/指针返回,即可以继续调用该对象的其他方法。通常来说,当某个对象需要一次调用多个方法来设置其属性时,就非常适合改造为链式调用了。
SQL语句中,非常适合链式调用:
1
2
3
|
s := geeorm.NewEngine("sqlite3", "gee.db").NewSession()
var users []User
s.Where("Age > 18").Limit(3).Find(&users) // 链式调用
|
其实就是分段设置子句:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func (s *Session) Limit(num int) *Session {
s.clause.Set(clause.LIMIT, num)
return s
}
func (s *Session) Where(desc string, args ...interface{}) *Session {
var vars []interface{}
s.clause.Set(clause.WHERE, append(append(vars, desc), args...)...)
return s
}
func (s *Session) OrderBy(desc string) *Session {
s.clause.Set(clause.ORDERBY, desc)
return s
}
|
实现示例:查询SQL并返回一条数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// First 返回第一行数据, 并构造成对象, 参数为对象地址
func (s *Session) First(value interface{}) error {
dest := reflect.Indirect(reflect.ValueOf(value))
destSlice := reflect.New(reflect.SliceOf(dest.Type())).Elem()
if err := s.Limit(1).Find(destSlice.Addr().Interface()); err != nil { // 链式调用
return err
}
if destSlice.Len() == 0 {
return errors.New("NOT FOUND")
}
dest.Set(destSlice.Index(0)) // 对原对象进行设置
return nil
}
|
钩子
Hook,翻译为钩子,其主要思想是提前在可能增加功能的地方埋好(预设)一个钩子,当需要重新修改或者增加这个地方的逻辑的时候,把扩展的类或者方法挂载到这个点即可。
比如,设计一个 Account 类,Account 包含有一个隐私字段 Password,每次查询后都需要做脱敏处理,才能继续使用。如果提供了 AfterQuery 的钩子,查询后,自动地将 Password 字段的值脱敏,就可以去除不必要的代码。
问:如何实现钩子?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
const (
BeforeQuery = "BeforeQuery"
AfterQuery = "AfterQuery"
BeforeUpdate = "BeforeUpdate"
AfterUpdate = "AfterUpdate"
BeforeDelete = "BeforeDelete"
AfterDelete = "AfterDelete"
BeforeInsert = "BeforeInsert"
AfterInsert = "AfterInsert"
)
// CallMethod 调用注册的 method
// method 是对象拥有的方法名, value 是对象的地址
func (s *Session) CallMethod(method string, value interface{}) {
// s.RefTable().Model 或 value 即当前会话正在操作的对象,
// 使用 MethodByName 方法反射得到该对象的方法。
fm := reflect.ValueOf(s.RefTable().Model).MethodByName(method)
if value != nil {
fm = reflect.ValueOf(value).MethodByName(method) // 得到该对象定义好的 method
}
param := []reflect.Value{reflect.ValueOf(s)} // 每一个钩子的入参类型均是 *Session
if fm.IsValid() {
if v := fm.Call(param); len(v) != 0 {
if err, ok := v[0].Interface().(error); ok {
log.Error(err)
}
}
}
return
}
|
比如实现:查询某行后,自动对密码字段脱敏:
- 设置钩子位置
1
2
3
4
5
6
7
8
9
10
11
|
func (s *Session) Find(values interface{}) error {
s.CallMethod(BeforeQuery, nil)
// ...
for rows.Next() {
dest := reflect.New(destType).Elem()
// ...
s.CallMethod(AfterQuery, dest.Addr().Interface()) // 钩子的位置放在查询完单行数据之后
// ...
}
return rows.Close()
}
|
- 给对象赋予
AfterQuery方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
type Account struct {
ID int `geeorm:"PRIMARY KEY"`
Password string
}
// 定义 AfterQuery 方法
func (account *Account) AfterQuery(s *Session) error {
log.Info("after query", account)
account.Password = "******"
return nil
}
func TestSession_CallMethod(t *testing.T) {
s := NewSession().Model(&Account{})
_ = s.DropTable()
_ = s.CreateTable()
_, _ = s.Insert(&Account{1, "123456"}, &Account{2, "qwerty"})
u := &Account{}
err := s.First(u)
if err != nil || u.ID != 1001 || u.Password != "******" {
t.Fatal("Failed to call hooks after query, got", u)
}
}
|
事务
Go 标准库 database/sql 提供了事务的接口,调用方法和 SQL 原生语句其实很像:
- 调用
db.Begin() 得到 *sql.Tx 对象,使用 tx.Exec() 执行一系列操作;
- 如果发生错误,通过
tx.Rollback() 回滚,如果没有发生错误,则通过 tx.Commit() 提交。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func main() {
db, _ := sql.Open("sqlite3", "gee.db")
defer func() { _ = db.Close() }()
_, _ = db.Exec("CREATE TABLE IF NOT EXISTS User(`Name` text);")
tx, _ := db.Begin() // 开启事务
_, err1 := tx.Exec("INSERT INTO User(`Name`) VALUES (?)", "Tom")
_, err2 := tx.Exec("INSERT INTO User(`Name`) VALUES (?)", "Jack")
if err1 != nil || err2 != nil {
_ = tx.Rollback() // 若发生错误,就回滚
log.Println("Rollback", err1, err2)
} else {
_ = tx.Commit() // 若正常执行,就提交
log.Println("Commit")
}
}
|
问:事务是如何实现的?
使用 sql.DB 对象执行 SQL 语句,会自动提交;若要支持事务,需要改成 sql.Tx 对象执行语句。
- 首先是封装一层,实现 Begin()、Commit()、Rollback() 方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func (s *Session) Begin() (err error) {
log.Info("transaction begin")
if s.tx, err = s.db.Begin(); err != nil { // 得到 sql.tx对象
log.Error(err)
}
return
}
func (s *Session) Commit() (err error) {
log.Info("transaction commit")
if err = s.tx.Commit(); err != nil { // 封装 Commit 方法
log.Error(err)
}
return
}
func (s *Session) Rollback() (err error) {
log.Info("transaction rollback")
if err = s.tx.Rollback(); err != nil { // 封装 Rollback 方法
log.Error(err)
}
return
}
|
- 实现一键式接口,用户只需要把所有的操作放到一个函数中,作为入参传递给
engine.Transaction(),发生任何错误,自动回滚,如果没有错误发生,则提交。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
type txFunc func(*session.Session) (interface{}, error)
// 主要做的事情就是,省略了用户自己调用 sql.tx.Begin() 和 sql.tx.Commit()、sql.tx.Rollback()
func (engine *Engine) Transaction(f txFunc) (result interface{}, err error) {
s := engine.NewSession()
// 开启事务
if err := s.Begin(); err != nil {
return nil, err
}
// 结束事务
defer func() {
if p := recover(); p != nil {
_ = s.Rollback()
panic(p)
} else if err != nil {
_ = s.Rollback()
} else {
err = s.Commit()
}
}()
// 这是用户传进来的所有操作
return f(s)
}
|
讲的时候:其实事务的实现非常简单,因为 go 的标准库 database/sql 本身就支持事务,比如用 sql.Tx 对象调用执行函数 Exec(),通过 Begin() 和 Commit(),就可以实现事务。
所以 orm 只需要在外面封装一层。比如说我定义了一个事务函数,就叫 Transaction() 吧,用户只需要把他的所有操作打包成一个 func,而 go 语言中 func 是可以当成 funcval 的,也就是可以当作另一个函数的入参,这样的话,就只需要在 Transcation 中帮助用户自动调用 sql.Tx 执行语句而不是通过 sql.DB 调用,并且写好 Begin(),以及错误处理导致 Rollback() 或 Commit() 的逻辑即可,然后在 Transaction 中调用用户定义的 func,就很方便的实现了事务~
数据库迁移
仅实现最基础的功能:
- 结构体(struct)变更时,数据库表的字段(field)自动迁移(migrate)。
- 仅支持字段新增与删除,不支持字段类型变更。
如 SQLite 中删除字段,其实有点麻烦的:
1
2
3
|
CREATE TABLE new_table AS SELECT col1, col2, ... from old_table
DROP TABLE old_table
ALTER TABLE new_table RENAME TO old_table;
|
- 首先需要将需要保留的字段,重新建个新表;
- 删除旧表;
- 将新表命名为旧表。
问:数据库迁移都实现了啥?
实现了新增或删除字段时,对数据库中的表进行自动修改。
这个过程需要利用事务,否则删掉旧表但是没建出来新表就不好了。总体是这样实现的:
- 根据新表和旧表的字段,求出:新增的字段,要删除的字段;
- 根据新增的字段列表,在旧表中新建这些列;
- 若删除的字段列表为空,就可以直接返回旧表;若删除的字段列表不为空,就需要从旧表中选择所需的列,新建新表,删除旧表,重命名新表为旧表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
// difference returns a - b 即: 新表 - 旧表 = 新增字段,旧表 - 新表 = 删除字段
// a: a表的字段 b: bb字段
func difference(a []string, b []string) (diff []string) {
mapB := map[string]bool{}
for _, v := range b {
mapB[v] = true
}
for _, v := range a {
if _, exist := mapB[v]; !exist {
diff = append(diff, v)
}
}
return
}
// Migrate 迁移表
// value: 新表的结构体对象
func (engine *Engine) Migrate(value interface{}) error {
// 利用事务 保持原子性
_, err := engine.Transaction(func(s *session.Session) (result interface{}, err error) {
if !s.Model(value).HasTable() {
log.Infof("table %s doesn't exist", s.RefTable().Name)
return nil, s.CreateTable()
}
// table 是新表的结构
table := s.RefTable()
// 查询旧表
rows, _ := s.Raw(fmt.Sprintf("SELECT * FROM %s LIMIT 1", table.Name)).QueryRows()
columns, _ := rows.Columns()
// 增加的列
addCols := difference(table.FieldNames, columns)
// 删去的列
delCols := difference(columns, table.FieldNames)
log.Infof("added cols %v, deleted cols %v", addCols, delCols)
// 在旧表中添加列
for _, col := range addCols {
f := table.GetField(col)
sqlStr := fmt.Sprintf("ALTER TABLE %s ADD COLUMN %s %s;", table.Name, f.Name, f.Type)
if _, err = s.Raw(sqlStr).Exec(); err != nil {
return
}
}
if len(delCols) == 0 {
return
}
// 只选旧表中指定列(即新表的所有列),转移到新表,删除旧表,新表改名为旧表
tmp := "tmp_" + table.Name
fieldStr := strings.Join(table.FieldNames, ", ")
s.Raw(fmt.Sprintf("CREATE TABLE %s AS SELECT %s from %s;", tmp, fieldStr, table.Name))
s.Raw(fmt.Sprintf("DROP TABLE %s;", table.Name))
s.Raw(fmt.Sprintf("ALTER TABLE %s RENAME TO %s;", tmp, table.Name))
_, err = s.Exec()
return
})
return err
}
|
四、负载均衡器